以前より試してみたかったCloud Vision API を試してみました。
Cloud Vision APIとは
こちらの動画をご覧になれば一目瞭然なのですが、Googleが公開した機械学習を利用した画像認識APIです。
物体や文字の認証だけでなく、人物の感情までも画像から認識できることが可能です。
使用量によって有料になりますが、個人利用程度(1,000ユニット以下)では無料で利用することが出来ます。
登録や利用の仕方はこちらで詳しく解説されています。
Cloud Vision APIの使い方まとめ (サンプルコード付き) - Syncer
Node Cloud Vision API

tejitak/node-cloud-vision-api - GitHub
JavaScriptで利用出来るクライアントも早くも公開されています。こちらは日本の方が公開されているNode.js向けのパッケージクライアントです。
かなり少ない記述量でAPIを利用することが出来ます。また、画像をBase64に変換せずに利用出来るので、通常のjpegファイルから画像認識を利用することが出来ます。
やってみた

お気に入りのRaspberry Piで試してみました。今回は顔認識(FACE_DETECTION)とカテゴリ認識(LABEL_DETECTION)を読み取るように指定しています。
でサーバーを立ち上げます。まずは満面の笑みで「Shutter」ボタンをクリックします。
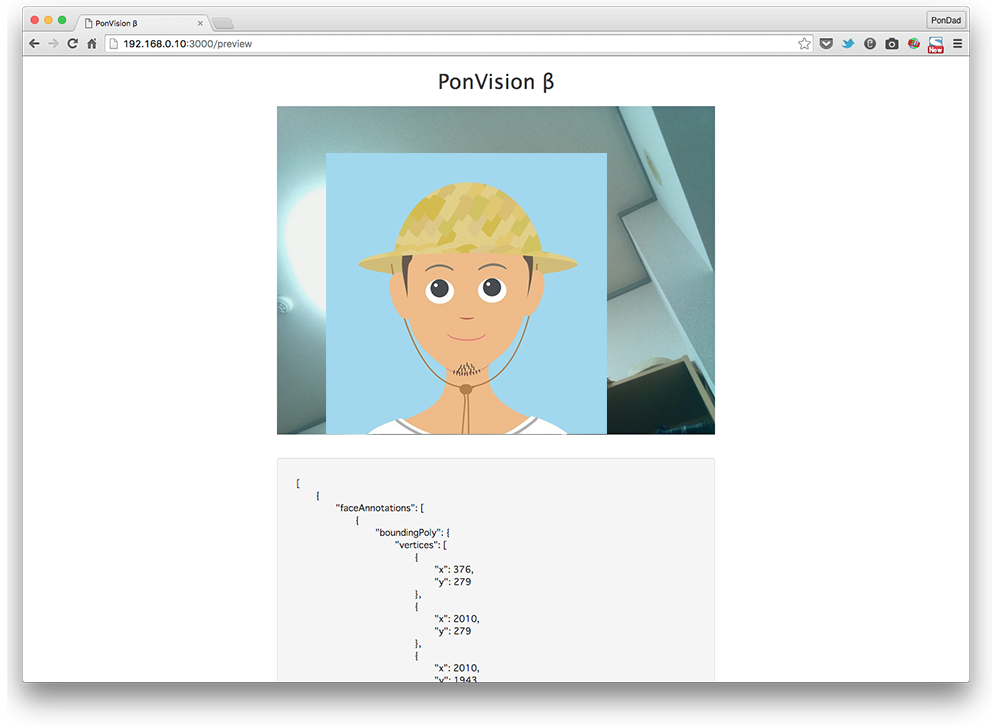
プレビュー画面に、Cloud Vision API から戻ったJSONデータを表示するようにしてみました。こんな感じです。
1 2 3 4 5 6 7
| "joyLikelihood": "LIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "VERY_UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "VERY_LIKELY"
|
かなり引きつった笑顔ではありますが、joyLikelihood が LIKELY と表示されています。
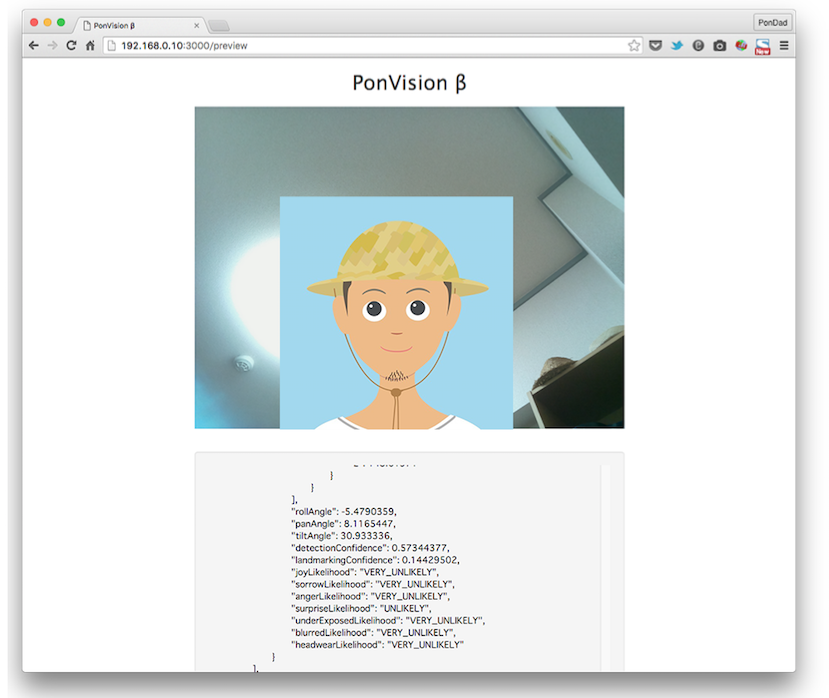
今度は口をあんぐり開けて驚いた表情を作ってみます。
1 2 3 4 5 6 7
| "joyLikelihood": "VERY_UNLIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "VERY_UNLIKELY"
|
今度はsurpriseLikelihood が UNLIKELY となっています。
怒ったり、泣いたり、といった表情も試してみたんですが、なかなか反応しませんでした。ひょっとしたらもう少し全身を映したものの方が感情認識はされやすいのかもしれません。
今度は物で試してみます。
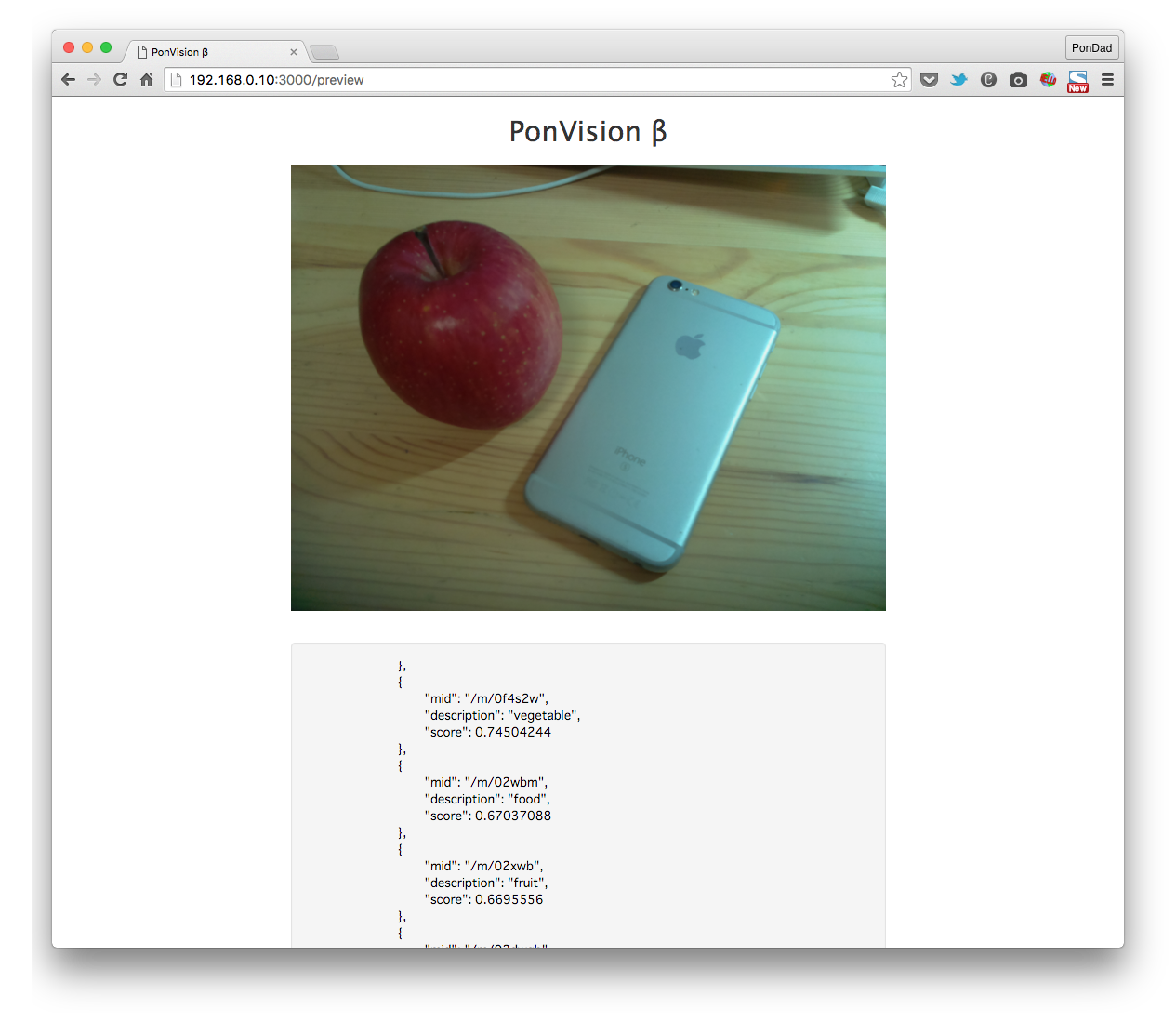
みんな大好き。「林檎」と「アップル」ですね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
| "labelAnnotations": [ { "mid": "/m/036qh8", "description": "produce", "score": 0.95910442 }, { "mid": "/m/05s2s", "description": "plant", "score": 0.86686105 }, { "mid": "/m/0f4s2w", "description": "vegetable", "score": 0.74504244 }, { "mid": "/m/02wbm", "description": "food", "score": 0.67037088 }, { "mid": "/m/02xwb", "description": "fruit", "score": 0.6695556 }, { "mid": "/m/02dwgb", "description": "input device", "score": 0.57699329 } ]
|
うーん、残念ながら期待したような「Apple」も「iPhone」も認識されませんでした。
画像認識は対象を複数指定知ることも出来ます。最後に、去年の夏におじいちゃんに撮ってもらった双子の写真を認識させてみます。(これはもちろんRaspberry Piで撮ったやつではありません)
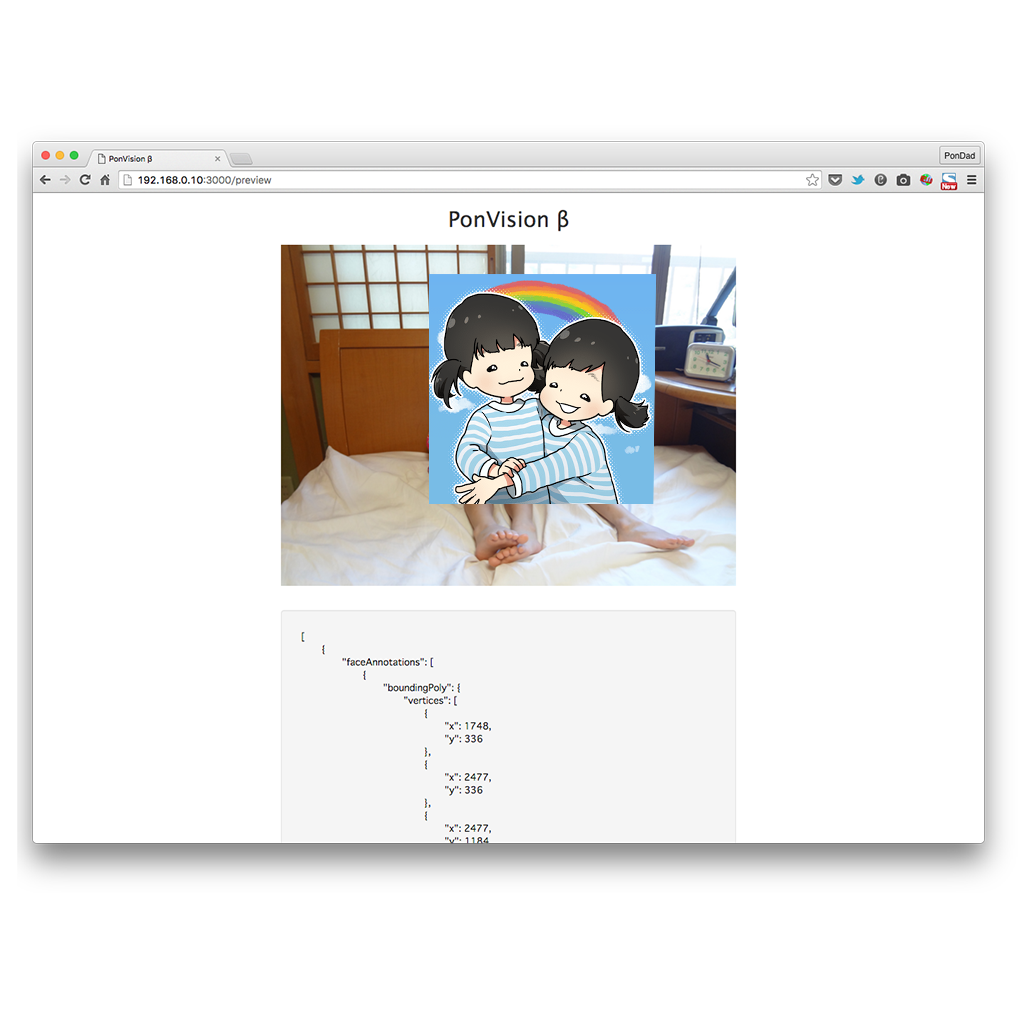
ひとりめ
1 2 3 4 5 6 7
| "joyLikelihood": "VERY_LIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "VERY_UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "VERY_UNLIKELY"
|
ふたりめ
1 2 3 4 5 6 7
| "joyLikelihood": "VERY_LIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "VERY_UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "VERY_UNLIKELY"
|
ふたりとも「とっても笑顔」と認識されました。
まとめ
最近の技術の進歩は驚くばかりで、冒頭の「Ras Pi ロボット」の様に表情に反応するロボットなんてのも個人で開発することが可能になっています。
Web関連でも画像認識や音声認識など様々なライブラリが公開されてますます楽しみが増えてきました。ではまた。
サンプルコード
PonDad/PonVisionβ -GitHub Gist