最近凝っていることは強化学習です。人工知能愛好家(Artificial Intelligence Hobbyist)ポンダッドです。
前回 初めてQ学習(強化学習の一種)をやってみて、限られた環境の中ではありますが、「報酬」を得るために機械が自主的に学んでいく手法を試してみました。
今回はどの様にすれば学習効果が上がるのかを試してみたいと思います。
Q学習のパラメータ

Q値を得る過程は、前回少し簡略化したものを利用したのですが、正しくは以下の様な式になる様です。
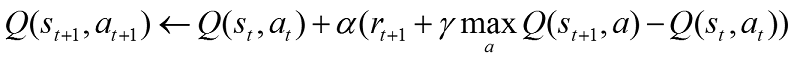
式の引用:静岡理工科大学情報学部コンピュータシステム学科・知能インタラクション研究室 - 強化学習
かなり難しくなってきました。変数をまとめてみましょう。
- S 「画面の配列」
- a 「アクション」
- r 「報酬」
- γ(ガンマ) 「割引率」
- α(アルファ) 「学習率」
「次」の「アクション」や、「次」の「画面の配列」を表すのに時間の経過を表す t を利用しているので少し変数が難しく感じますが、前回試した最短経路で部屋を脱出するときに利用した変数 S’ や a’ と同じです。
ただし、今回は α 「学習率」 が追加になっています。これは報酬の予測を一度にどれ位更新するかを指します。
これらに加えて、行動選択の割合をε-greedy法で得るため
- ε(イプシロン) 「行動選択率」
を設定します。ムムム…かなり難しくなってきました。
実際にこれらの式をPythonで実装しているプログラムサンプルがありますので、実行しながらみていくことにしましょう。
rlcode/reinforcement-learning - GitHub
こちらのレポジトリの /Code 1. Grid World/5. Q Learning/ を利用しながらみていくことにします。

これは分かりやすいですね。「●」がゴール「▲」が障害物で「■」がゴールに向かう最短の行動を学習させる例題です。
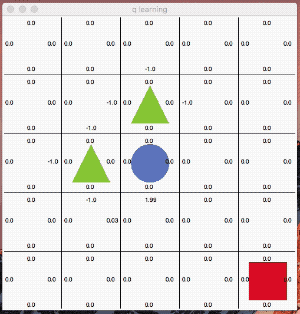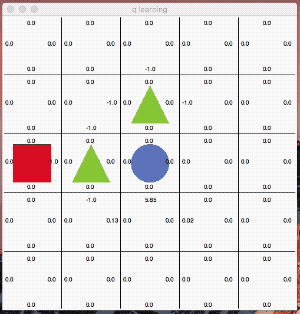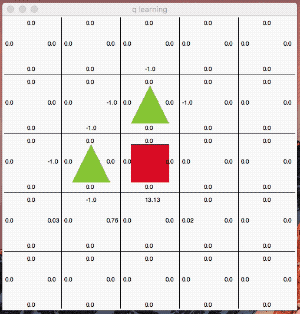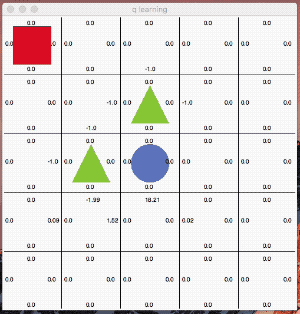
ゴールした際に得られる報酬を元にしてQ値を更新しています。学習のエポックは1,000回です。学習が進むにつれて、障害物を避けながら最短距離を選択する様になっています。
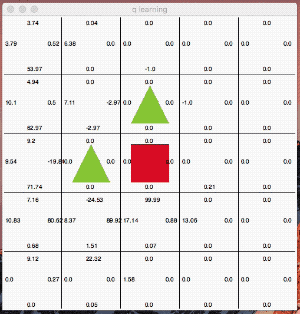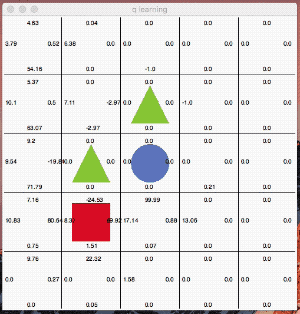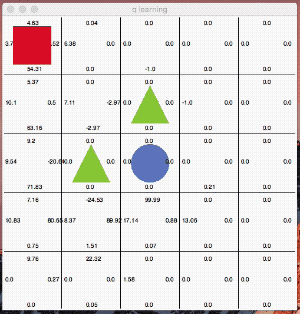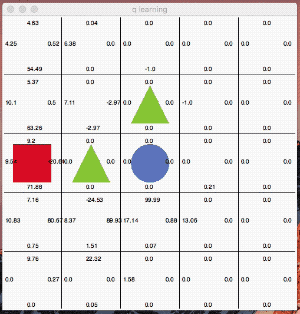
最終的に最短距離を選んで行動する様になりました。面白いのはQ値が高い行動を単純にトレースしているのではないところです。
絶えず「探索」の意思を持ちながら行動しているのが分かると思います。
コメントが韓国語だったのですが、Googleで翻訳したところ非常に簡潔に書かれていました。レポジトリもとても簡潔にまとまっていたので、コードを転記したものを参考までGistに上げておきました。
agent.pyの28行目からQ関数を更新しています。
|
|
シンプルに書かれていますが、上述の式通りにQ関数を更新しているのが分かると思います。
これをrun.pyの4行目からのdef update()内でwhileループを利用して変数を代入して更新します。
|
|
さて、Q学習をするに当たり、冒頭でパラメータを以下の様に設定しています。
agent.pyの5行目から
|
|
ここで関数 α(アルファ) γ(ガンマ) ε(イプシロン) を設定しているのが分かると思います。
ここでは適正なパラメータ設定により最短経路を算出していますが、これらを変更するとどうなるのでしょうか?実際にやってみることにします。
冒険させる - ε(イプシロン)を下げる
上述のサイトよりε-greedy法に関して引用します。
行動の選択方法として、ε-greedy法がよく使われる。これは一定の確率εで、或る環境sから取り得る行動のうち一つをランダムに選び、1-εの確率で或る環境sから最大のQ値を持つ行動aを選択する。
比較的簡単なモデルで0.9、「探査」が必要な少し複雑なモデルでも0.8位で設定される事が多い様です。
ここではe_greedy=0.2と極端に「探査」をさせてみます。

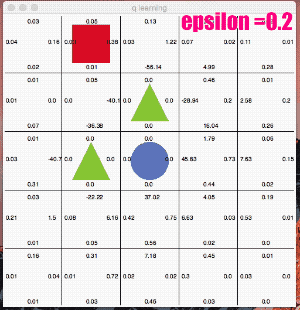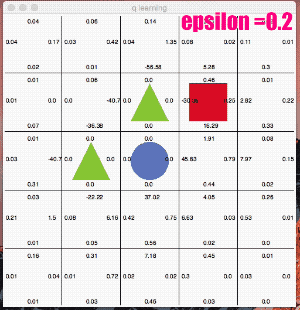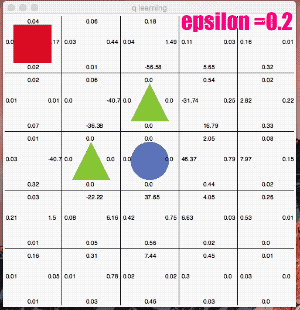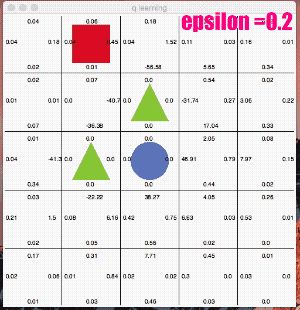
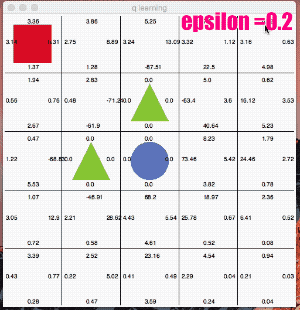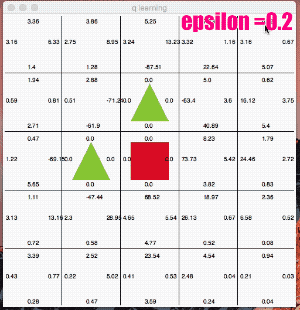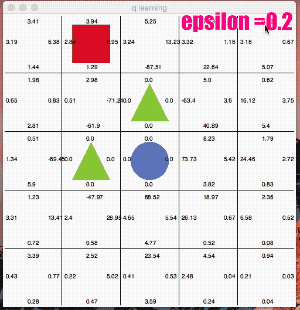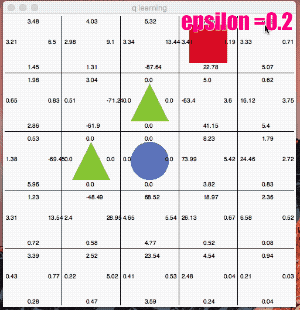
かなり冒険しています。なかなか学習の収束が進みませんが、右回りルートを発見し、最終的には右回りの最短ルートのQ値が高くなりました。
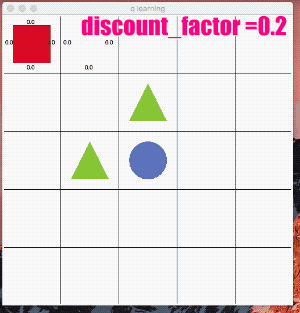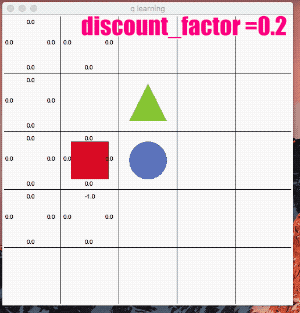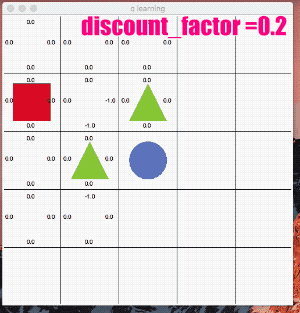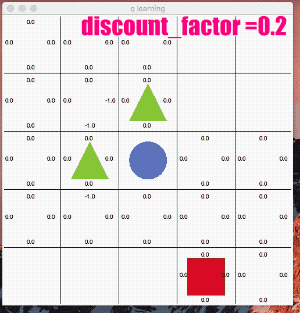
鬱にする - γ(ガンマ)を下げる
「割引率」γ(ガンマ) は0.9~0.99くらいにする事が多い様です。
γが0に近いと目先の利益を考慮して行動を選択し、γが1に近いほど長期的な報酬を考慮するアルゴリズムになります。
試しに思い切りパラメータを下げ、目先の事しか目に入らない様な鬱状態にしてみます。


とりあえずのまとめ
4月にここまで書いたのですが、パラメータの調整が上手くいかず中断しました。もう少し理解が進んだら再開したいと思います。