クリスマスまでにつくろうと思っていた相棒Bot(AI-Bot)ですが、時はすでに年末を迎えようとしています。皆さんいかがお過ごしでしょうか。ポンダッドです。
Speech Recognition API
さて、喋る人工無脳を作るにあたり、まずは言葉をブラウザで認識させられないか試してみました。
W3Cのドキュメントをベースにサンプルコードが公開されていたので[^1] 、そちらを参考にまずはマイクに話しかけた言葉をブラウザに書き出してみました。
iOS版のChromeでは機能しませんので一応スクリーンショットを載せておきます。
Speech Recognition APIを利用することでこの様にブラウザのマイクにアクセスすることが可能になります。
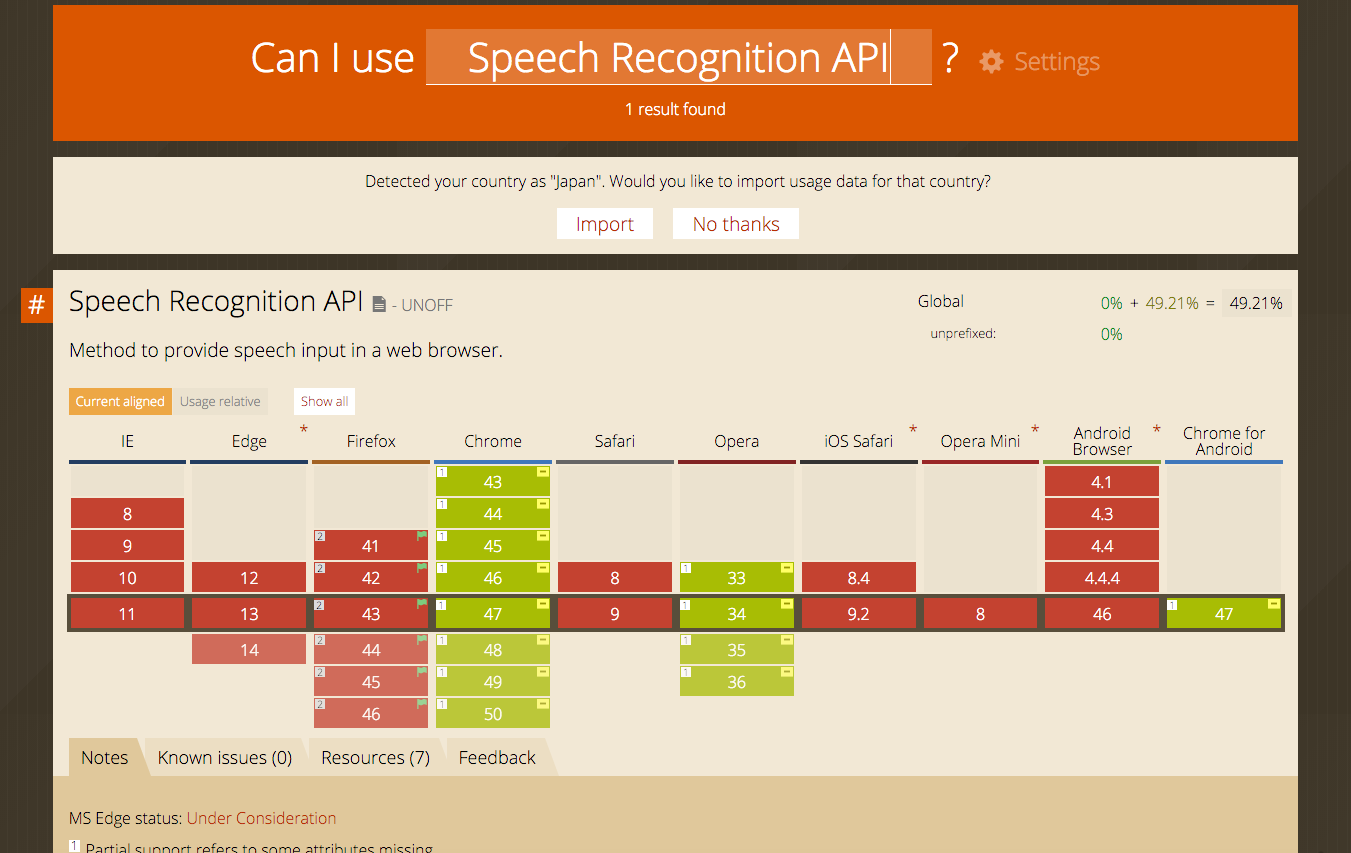
caniuse.com によれば、ChromeとOperaにしか今のところ対応していないみたいですね。
最新版のAndroid版Chromeには対応した様なので、Androidユーザーの方はモバイル環境でもこのAPIを利用することが可能です。
使い方は、簡単…とはいかずちょっと記述に工夫が必要です。
W3Cのドキュメント のサンプルコードはこんな風に記述されています。
|
|
最初event.results[i][0].transcript この部分がよく分からなかったのですが、どうもこういう事のようです。[^2]
音声を読み込んだ結果はAPIで自動的に認識してくれます。複数の候補 results の中から一番有力な結果 result を抽出します。
サンプルコードの例で言うと音節単位の解析結果が results となり、その配列が格納された変数が [i] となります。
変換結果が result となり、その候補の一番目を表す配列として [0] で格納します。
要約するとこのメソッドを利用することで、APIが音声を自動的に解析してくれて、一番可能性が高い単語をピックアップしてくれます。(すいません。こんな理解で。)
まあ、何はともあれ音声認識の抽出には成功しました。続いてBotっぽくする為に、読み上げた言葉に反応するようにしてみました。
単純な方法ですが、条件分岐を利用して音声Aに対しては返事A’、音声Bに対しては返事B’を返答するようにしてみました。
未対応ブラウザでご覧の方も多いと思いますので動画を添付しておきます。(ChromeBookです)
下手な英語の発音でもなんとか理解してもらえました。
まとめ
サミュエル・L・ジャクソン風の相棒Bot完成に、一歩近づきました。次回は返事をブラウザに喋らせてみます。
(この記事つづく)