人工無脳の会話に少し変化をつけられないか考えてみました。
人工無脳Eliza
人工無脳の起源として有名なプログラムとして”Eliza”がよく挙げられます。
ELIZA(イライザ)は初期の素朴な自然言語処理プログラムの1つである。対話型(インタラクティブ)であるが、音声による会話をするシステムではない。スクリプト (script) へのユーザーの応答を処理する形で動作し、スクリプトとしてはDOCTORという来談者中心療法のセラピストのシミュレーションが最もよく知られている。人間の思考や感情についてほとんど何の情報も持っていないが、DOCTORは驚くほど人間っぽい対話をすることがあった。MITのジョセフ・ワイゼンバウムが1964年から1966年にかけてELIZAを書き上げた。いわゆる人工無脳の起源となったソフトウェアである。- Wikipedia
1960年代に作られたプログラムですが現在でもWebで試すことが出来ます。以下、JavaScriptで組まれたWebアプリケーションです。
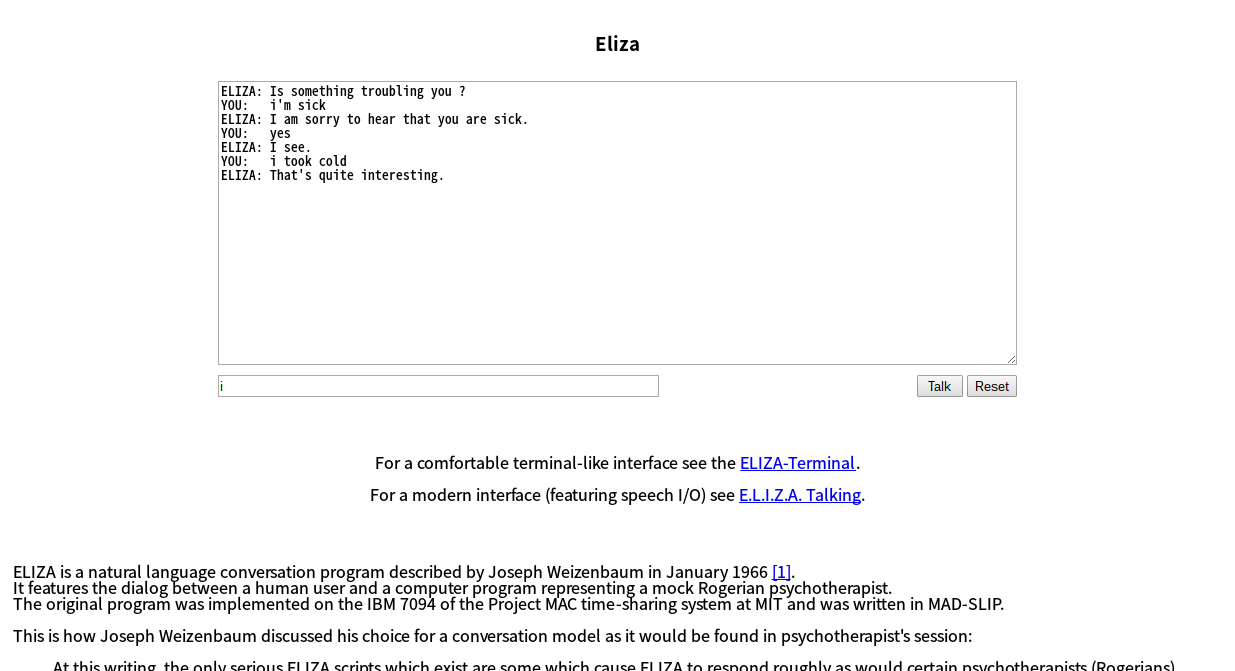
英語なので正確には分かりませんが、確かにキーワードに対して応えるアシスタント型の人工無脳とは違う反応をします。
以前仕事で受講したことのあるコーチングの「傾聴」の様な反応です。例えばこんな感じです。
YOU: I have trouble with my children.(私は私の子供のことで問題を抱えています。)
ELIZA: What else comes to your mind when you think of your children ?(あなたが子供を考えるとき、他にどんな事を考えますか?)
回答を相手から引き出す見事な技法を駆使しています。こんな感じでElizaは自分から答えは言いませんが、対話相手が自ら回答を見つけるような反応をします。
では、どんな仕組みになっているか見てみることにします。
Elizaの仕組み
上記のサイトでは仕組みをこんな風に解説しています。
|
|
単純にキーワードに対して回答を出すのではなく、「キーワード」に対して「ランク」を指定し、「形態素」を「再構築」する。という仕組みです。ちょっと分かりづらいのでサンプルを一つ拾ってみます。
|
|
Elizaの中身は「dreamed」に対してこんな風に反応する様に書かれています。実際に質問してみます。
YOU: I dreamed my children are growing up.(私は子供たちが成長している夢を見ました。)
ELIZA: Have you ever dreamed your children are growing up before ?(あなたは今まで、子供たちが成長している夢を見たことがありますか?)
こんな風にキーワードに沿った回答をします。ポイントになるのは「dreamed」のランクが「4」となっているところです。
「are」のランクは「0」、「my」は「2」、「dream」は「3」となっているので、ランクの高いキーワード「dreamed」に対する回答が優先されるという訳です。
「英語の部分を日本語に置き換えれば日本語版が出来るんじゃないか?」と一瞬思ったのですが、そう簡単にはいきません。
日本語の形態素解析
英語ならば形態素(言語の最小単位)ごとにスペースが空くので、そもそも形態解析が必要ありませんが、日本語ではそうも行きません。
上記のキーワード様な「夢」と「夢にみた」「夢みた」など名詞と動詞の判別も難しく、一筋縄ではいきません。
困った…。
これは先人たちの開発した日本語形態素解析のプログラムを利用することで解決出来ます。例えば京都大学とNTTコミュニケーションズが共同開発したオープンソース形態素解析エンジン「mecab」。
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
mecabとIPA 辞書をインストールし、コマンドラインで実行するとこの様に形態素解析を行ってくれます。
|
|
この様に品詞まで合わせて日本語の形態素解析が可能になります。
JS+Node.jsによるWebクローラー/ネットエージェント開発テクニック
日本語版Elizaは今では開発されることも無く、公開サンプルなど検索してもは見当たりませんでした。
有償の書籍になりますが、こちらの書籍でサンプルが公開されています。

JS+Node.jsによるWebクローラー/ネットエージェント開発テクニック - Amazon.jp
「第7章 04人工無能と会話しよう」の中で詳しく解説されています。以下引用です。
このプログラムでは、以下のようにして会話をします。
1.ユーザーから入力を得る
2.入力を形態素解析
3.各単語についてデータベースで調べる
4.もし一致するものがあればその返答を返す
プログラムはNode.jsで動き、データベースはmongoDBを利用します。サンプルコードも書籍の付録でダウンロードする事が出来るので手軽に試すことが出来ます。
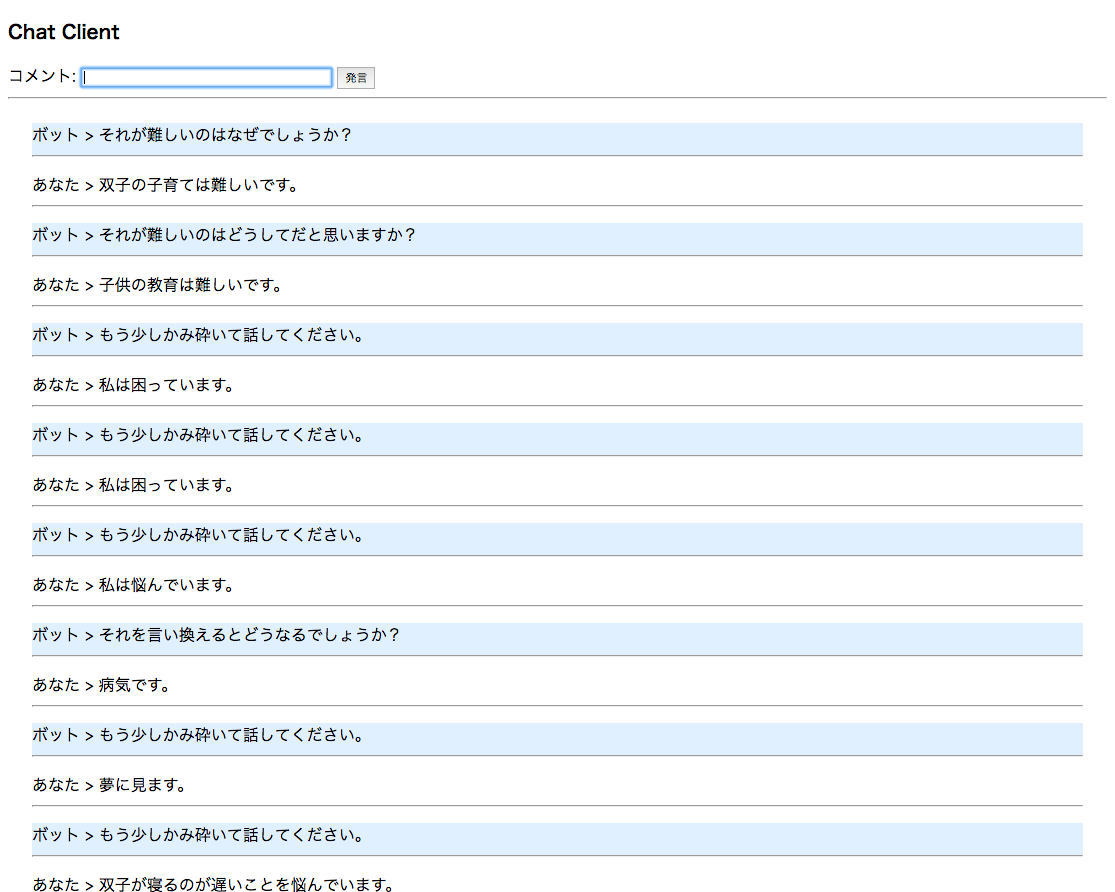
データベースのjsonデータはリクエストを送ると、この様に返ってきます。
|
|
具体的にはこのような感じです。
|
|
英語と違って相手が話した言葉を「それが」「それは」と回答することで対話型の返答になっています。
ajaxを利用しているので、/api をエンドポイントに?msg=hoge とリクエストを送るとjsonでレスポンスを返します。
ローカルマシン(ここではMac)のIPアドレスを利用してAPIとして利用することも可能です。GETリクエストのため「こんにちは」をエンコードしてAPIリクエストしてみます。
|
|
BOTからレスポンスを取得出来ました。
hubotからEliza型人工無脳を利用する
Eliza型人工無脳を起動するローカルマシンでhubotを起動し、APIリクエストを送り、レスポンスをSlackに投稿してみます。
hubotスクリプトはこのような記述しました。
|
|
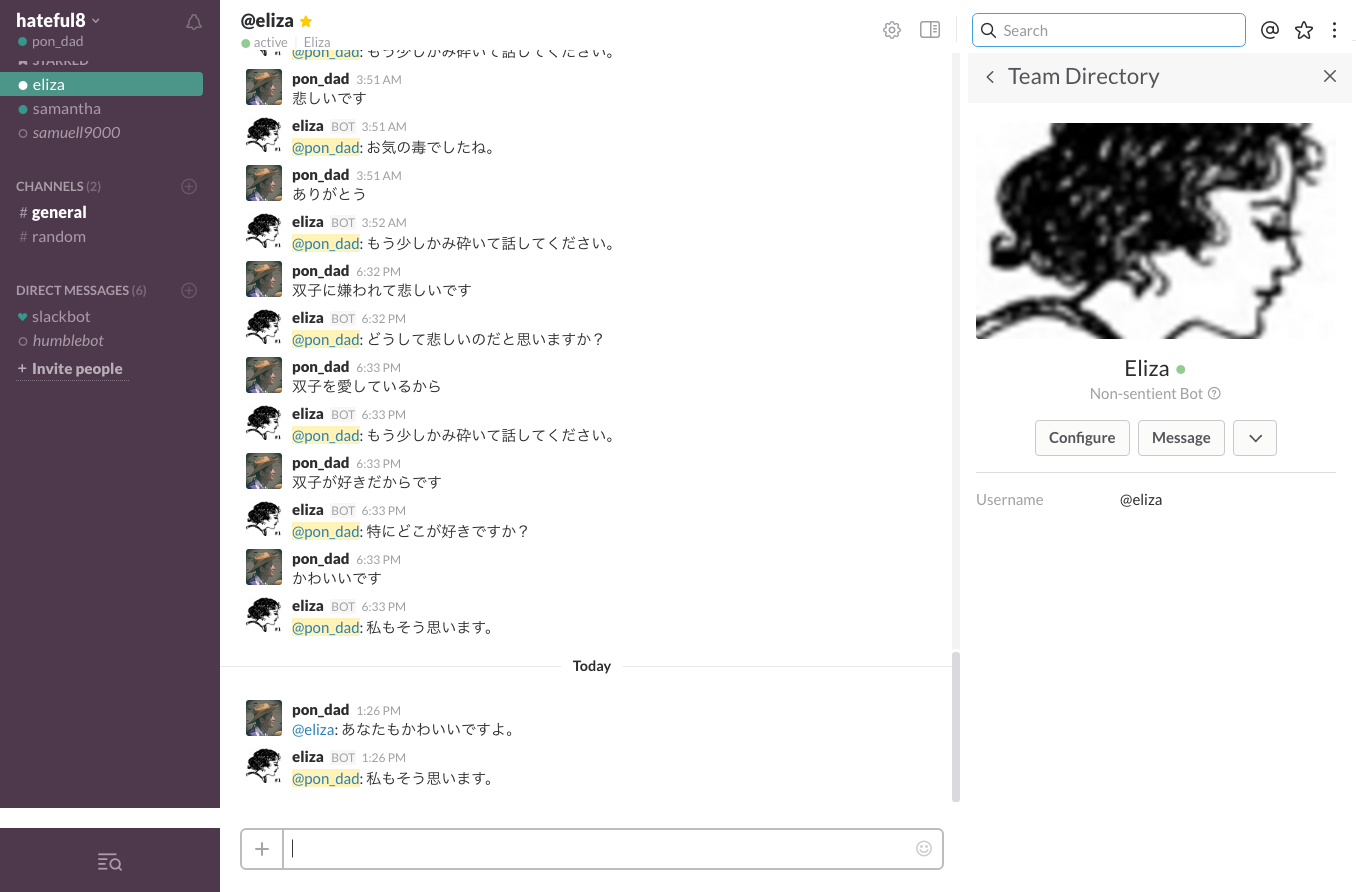
hubotでEliza型人工無脳が動きました。
まとめ
書籍のサンプルコードを丸ごと利用する事になりましたが、Eliza型の人工無脳の仕組みを理解することが出来ました。
本当は人工無脳部分をherokuにアップロードし、APIとして利用したかったのですが、mecabの設置がうまく行かなかった為、今回はローカルでの実行になっています。