少し前ですがBotに映画を観せてセリフを記憶させ「機械が勉強してるから機械学習。なんちゃて、えへ。」みたいなことをしていました。ポンダッドです。
それはさておき、教科書を見ながら機械学習ライブラリ「scikit-learn」を使ってみました。
scikit-learn
Pythonの機械学習では定番のライブラリだそうです。比較的インストールがし易く、デフォルトのモジュールで利用出来ます。
機械学習というと難しい数式による解説が多く出てくる印象が強いのですが、こんな風に3Dグラフを利用して視覚化する事も出来ます。
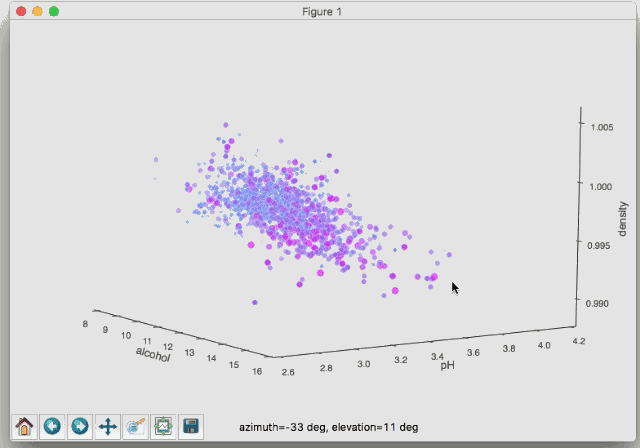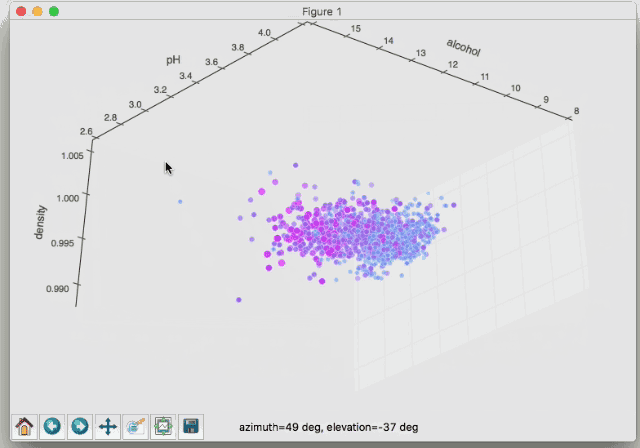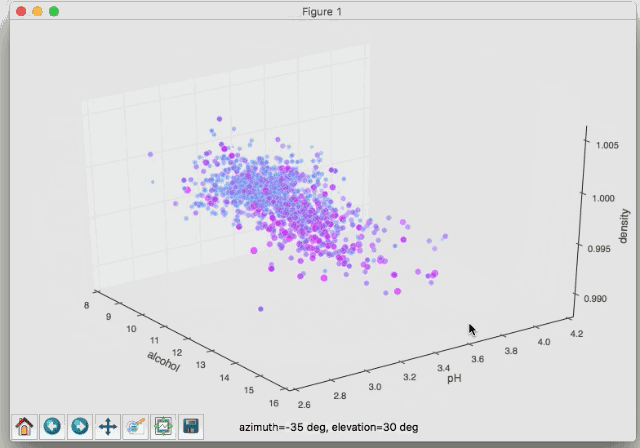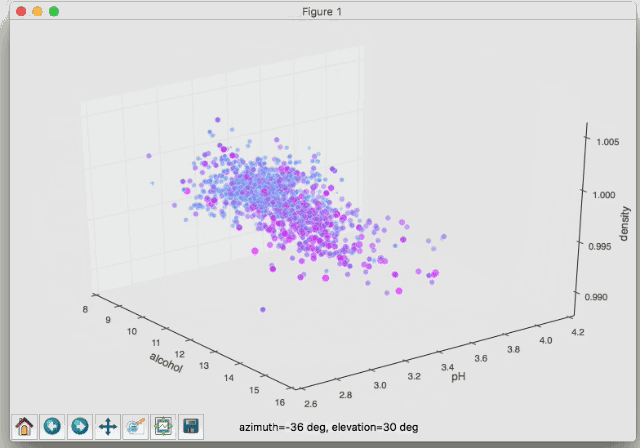
これは赤ワインの成分を示しているグラフで、色が赤くなるほど美味しいということになります。「密度(濃度)」「ph値」「アルコール度数」を3軸に取っています。
成分と美味しさ(品質)を一覧にしたデータを元に「機械学習」を行うことで、成分を元にしてワインの味を判定する事が出来ます。
こんな感じです。
|
|
「うわ。AIソムリエ誕生か?」などど少し心配になりますが、慌てずに仕組みがどうなっているか試してみることにしましょう。
実践力を身につける Pythonの教科書 - Amazon.co.jp に沿って、自分なりに注釈を加えながら進めてみます。
データを準備する

機械学習を始める際、まずは公開されているデータセットを利用するのが良いようです。
UCI Machine Learning Repository
こちらの/wine-qualitywinequality-red.csvファイルを利用させてもらいます。
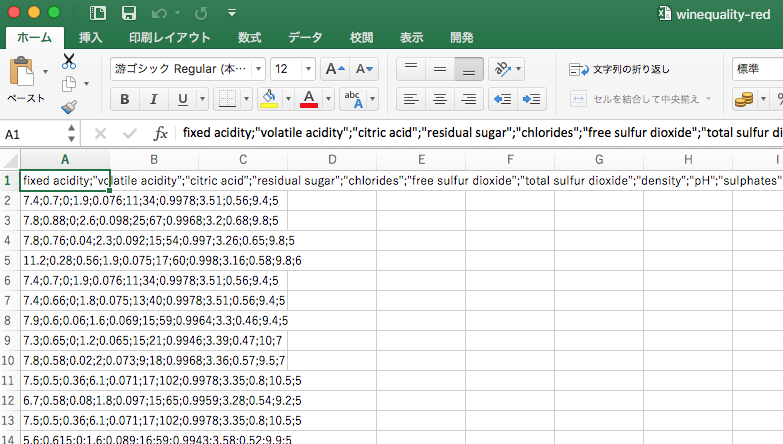
元になるデータは普通のカンマ区切りのテキストファイルで、1600弱のワインデータが格納されています。試しに利用するには十分ですね。
|
|
with構文を利用してcsvファイルを読み込みます。一行づつ読み込みを行った方が負荷が少なくて良い様です。変数red_csvにCSVを一行づつ書き込みます。
リストに[1:]を指定し、最初の行は除いて格納します。
データを学習させる
格納したデータは成分ごと12項目に分かれており、最後に品質が来ます。ここでは成分の11項目dataと品質1項目labelをそれぞれ分けてリストに格納します。
|
|
「scikit-learn」にはデータを学習させる様々なアルゴリズム(訓練機)があります。ここではSVMを利用した訓練を行いました。
モデルを評価する
訓練した結果を元にテスト用のデータを使って予測する事が出来ます。
|
|
訓練用のデータとテスト用のデータの割合に寄っても精度が変化します。テスト段階では十分なテスト用データが必要です。
チューニングする
「scikit-learn」で利用出来る様々なアルゴリズムを利用してチューニングし、予測精度を高めます。
|
|
ここではRandomForestというアルゴリズムを利用した場合が一番精度が上がりました。
|
|
冒頭の例の様に任意のデータをテストデータに指定すれば、学習結果を元にlabel(ここでは「品質・美味しさ)が正しいか差異を確認する事が出来ます。
まとめ
ざっくりとですが機械学習の大まかな流れが掴めた気がします。画像の学習も試してみたいですね。では。
参考書籍

実践力を身につける Pythonの教科書 - Amazon.co.jp
今回はこちらのChapter5-5「機械学習でワインの美味しさを判定しよう」を参考にしながら試してみました。3Dグラフの作成方法もサンプルプログラム付きで詳しく説明されています。
ポイントを抑えた解説がされているので、Pythonが初めての方にもおすすめです。是非。