機械学習の基本となる「MNIST」を試してみました。(相変わらず読み方がわかりません。むにすと?)ポンダッドです。
iPhoneのメモアプリを使って数字の「4」を書いてみます。

この画像(test4.png)を以下のスクリプトで読み込み、機械学習の結果と照合してみます。
|
|
実行します。
|
|
iMacさんがきちんと数字の「4」と判別しました。
MNIST

機械学習の基本として良く利用される「0〜9」までの数字の判別ですが、基本となるデータセットはこちら(THE MNIST DATABASE)で取得することが出来ます。
手書き数字の白黒画像は、サイズ28×28・明度0〜255です。それが6万点保存されています。
機械学習ライブラリscikit-learnでは、チュートリアルで利用する際にもう少し簡易的に行えるようにサイズや明度を簡略化したものがデフォルトで用意されています。
ちょっと中身をみて見ることにしましょう。
|
|
scikit-learnに保存されているdatasets(数字フォルダ)のうち、一つをCSVデータ(data.csv)として取り出してみます。
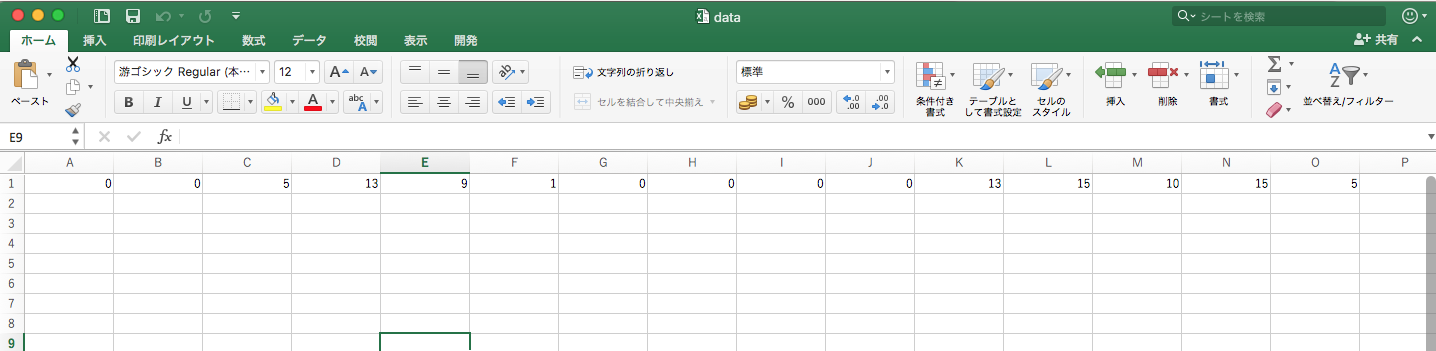
画像の1ピクセルあたり明度0〜15と簡略化されています。サイズも8×8ピクセルと小さいサイズですので、明度0〜15が64次元の配列に格納されています。サンプルは1,800点ほど保存されています。
Pythonのグラフ描写モジュール「matplotlib」を利用してみて見るとこんな感じです。
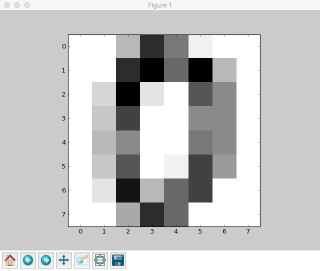
手書き文字をバイナリ化する
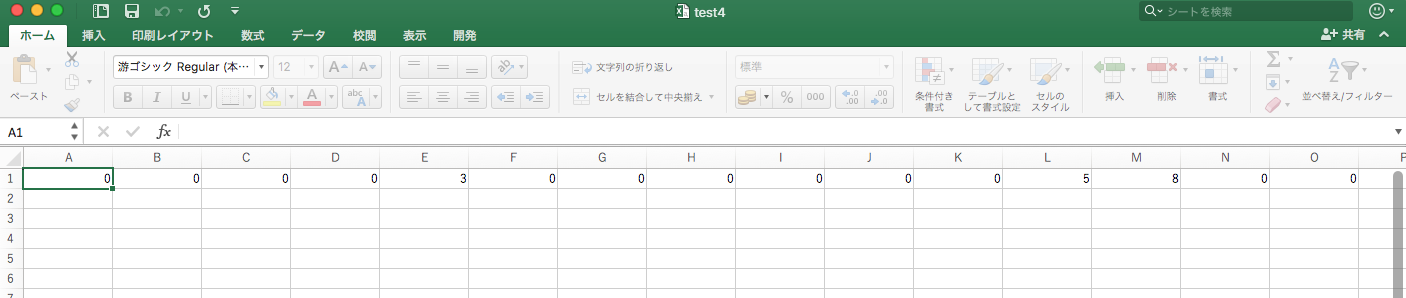
先ほどの手書き文字を同じようにデータ化してみます。教科書を参考にこんな風に書いてみました。
|
|
前回記事で試してみたNumPyモジュールを利用して、明度を書き換えています。
通常のpng画像の明度は0〜255なので、サンプルデータに合わせて0〜15に変換しています。
こういった計算もモジュールを利用することで簡易に記述出来るという訳です。
手書きデータを配列に格納する事が出来ました。先程と同様matplotlibを利用して画像を確認してみます。
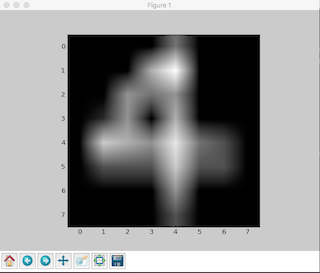
png画像を.convert('L')メソッドを利用しているので画像が反転しています。
学習する
パラーメータのチューニングは良く分からないので、教科書のサンプルをそのまま利用しました。
|
|
学習データ・学習ラベルを利用して学習し、テストデータを元にテストラベルを解析します。
まとめ
かなり簡略化されたデータですが、画像データを元に機械学習行う手法を確認してみました。
画像はデータ量も多いので、解析するのに処理能力が必要になります。分類する特徴を見極めたり、データを上手く圧縮したりといった工夫が必要なのかなと思います。
APIなどではなく、自分が所有するMacが画像を認識出来るようになり、少し人工知能っぽくなってきました。今後の成長(?)が楽しみです。では。
参考書籍

実践力を身につける Pythonの教科書 - Amazon.co.jp

Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう