こんにちは、人工知能愛好家(Artificial Intelligence Hobbyist)ポンダッドです。今年はこれで行こうかなと思っています。
さて、再び前回からの続きとなります。

今回はいよいよ畳み込みニューラル・ネットワークの中身を覗いて見たいと思います。カラー画像(3チャンネル)で見ていきたいところなのですが、まずは白黒画像(1チャンネル)で試して見たいと思います。
畳み込みニューラル・ネットワークでMNIST
MNISTを畳み込みニューラル・ネットワークを使い深層学習してみます。サンプルはmnist_cnn.py - GitHubを利用しました。
|
|
今回も、1,5,6の項目に関しては、通常の機械学習の流れと同じなので、2,3,4の部分をみていくことにします。特に「2.モデルの定義」の「Convolution層」と「Pooling層」がどのような処理をしているかを重点的にみていきます。
モデルの学習
プログラムを実行した結果はこの様になりました。
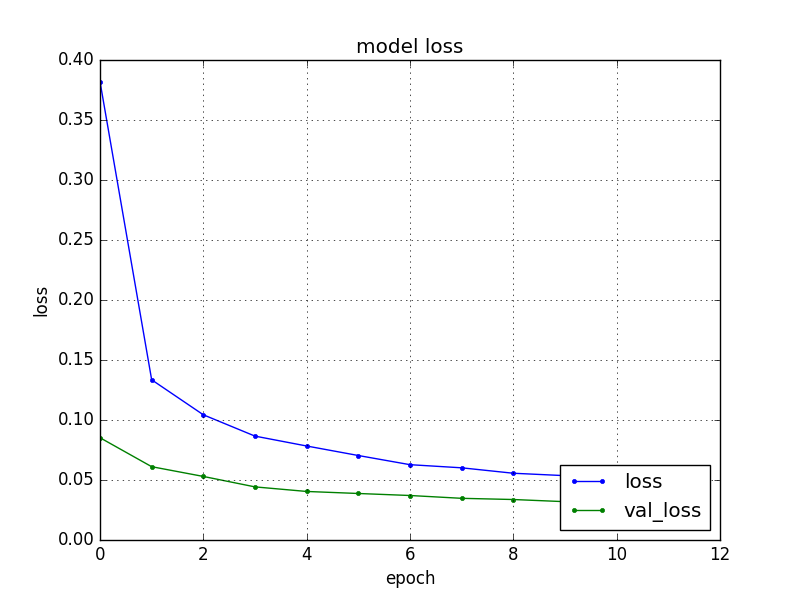
エポックnb_epochは12回実行し、loss(訓練データの損失)が順調に下がっていることが分かります。val_loss(検証データの損失)をみた限り過学習も起こしていません。
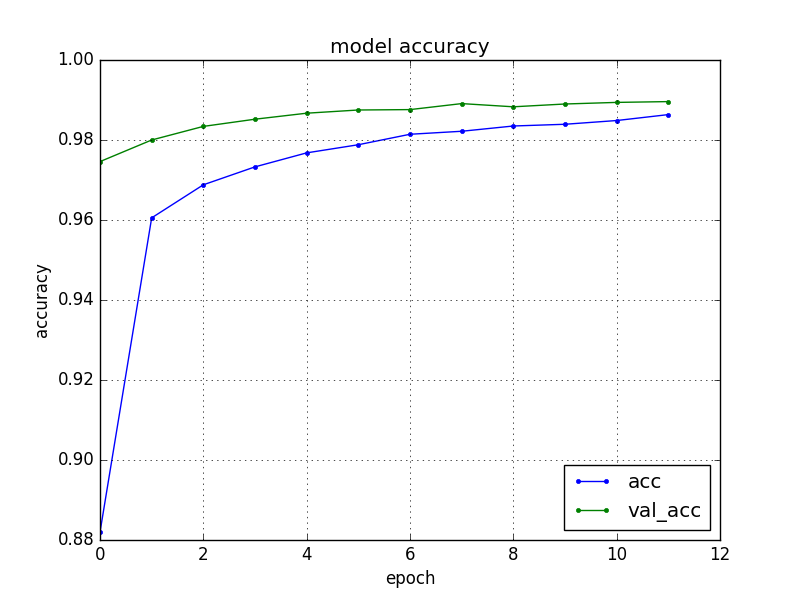
acc(訓練データの精度)は回数を重ねる毎にval_acc(検証データの精度)が上がっていることが分かります。最後にacc: 98.96%と言う結果になりました。
この部分のプログラムは以下の通りです。
|
|
nb_epoch=12で12回繰り返し学習し、batch_size=128ですので、データ128個分の誤差で重みを1回更新しています。
モデルのコンパイル
この部分のプログラムはこの様になっています。
|
|
loss='categorical_crossentropy'で予測モデルを指定し、optimizer='adadelta'で最適化アルゴリズムを指定しています。
モデルの定義
前回記事と同じく、Keras.js Demos のデモ画面をみながらどんな処理をしているのか見ていきたいと思います。
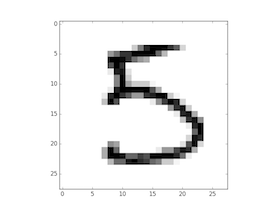
元になる画像はこの様な32×32ピクセルの1チャンネル画像です。色調は255ですが、事前に正規化して0.0~1.0の間の数値に置き換えています。
さて、いよいよ畳み込みニューラル・ネットワークの中身をみていくことにします。
Convolution層の処理

|
|
input_shape=(28, 28, 1)は28×28ピクセルの1チャンネル画像ということでわかるのですが、その他はどんな処理をしているのでしょうか?なんで元の画像よりちょっと小さくなっているのでしょうか?
人工知能に関する断創録さんの記事より引用させて頂きます。
Convolution2Dのborder_modeをvalidにすると出力画像は入力画像より小さくなる。
畳み込みニューラルネットのパラメータ数はフィルタのパラメータ数になる。例えば、最初の畳み込み層のパラメータ数は、32×1×3×3+32=320 となる。32を足すのは各フィルタにあるスカラーのバイアス項。
ちょっと難しいのですが、以下の画像を見ると少しイメージ出来ます。
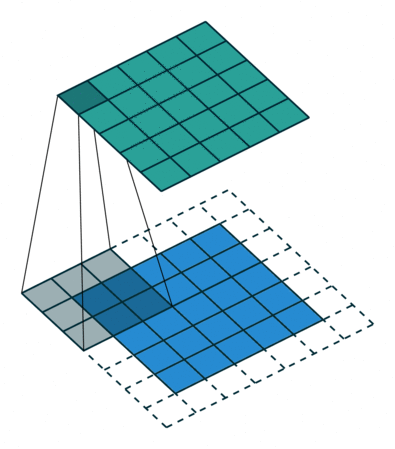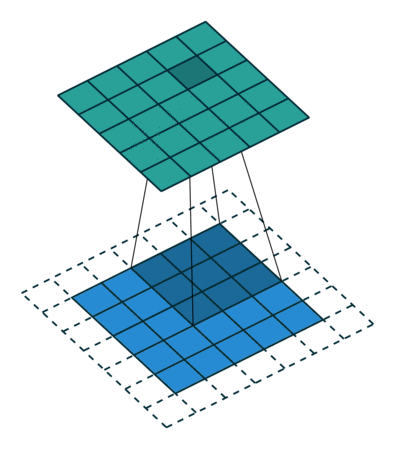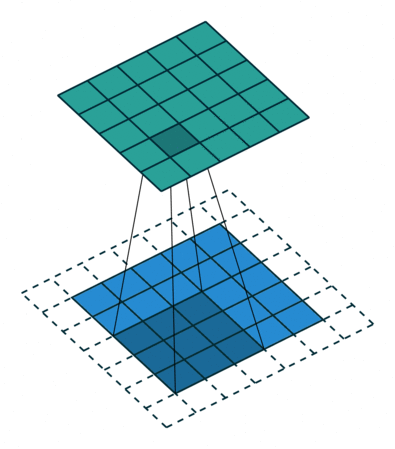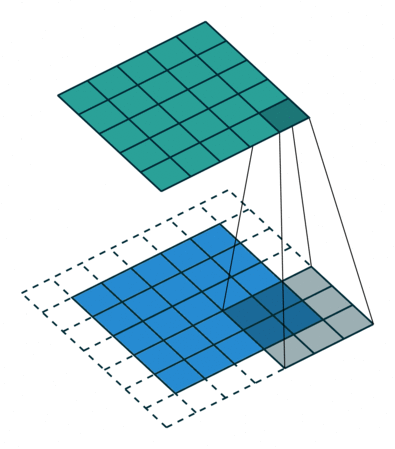
vdumoulin/conv_arithmetic - GitHub
この様に部分的に切り出した入力データに重み(フィルター)を掛け、更にバイアスを足していきます。これによって、周囲の情報から元のデータを圧縮することが可能になります。
今回はborder_mode='valid'の指定をしているので一回り小さくなっているんですね。
これがConvolution層(畳み込み層)の役割となります。
活性化関数(ReLU)

|
|
隠れ層に活性化関数を使うことは通常のニューラル・ネットワークと同様です。
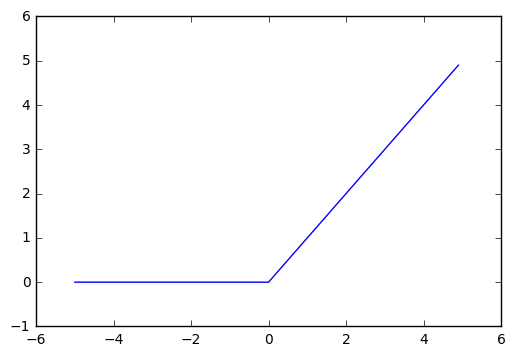
これがrelu関数ですね。
ここでは同じ処理を2回繰り返します。


|
|
特徴量が明確になったのでしょうか?人の目には分からない特徴量なのかもしれません。
Pooling層

|
|
さて、もう一つポイントとなる「Pooling層」の処理をみていきます。
画像の大きさも随分小さくなってしまいました。これはどういう処理をしているのでしょうか。
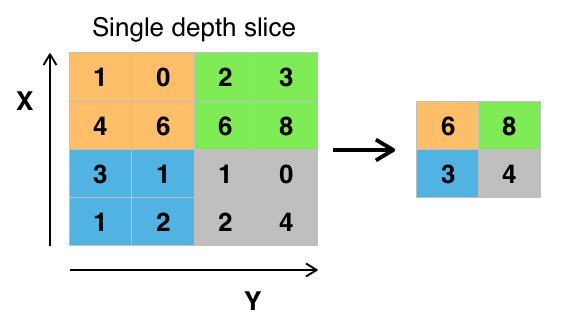
図で見ると「Convolution層」の処理と似ています。違いはデータに重み(フィルター)を掛けていないことです。
MaxPooling2Dという指定の通り、指定された2×2データの中から一番数値の高いデータを抽出していく処理になります。
ここではサイズが1/4の14×14のデータに圧縮されました。
ドロップアウト

|
|
画像的には変化がみられませんがここで「ドロップアウト」という処理をしています。Kerasのドキュメーションには以下の通り。
入力にドロップアウトを適用する。ドロップアウトは、訓練時のそれぞれの更新において入力ユニットのpをランダムに0にセットすることであり、それは過学習を防ぐのを助ける。
同じフィードバックを受け続けると過学習を起こしてしまうため、この様な処理をする様ですね。
全結合






|
|
ここからは全結合ニューラル・ネットワークと同様の処理となります。
平坦化したのち、128次元の隠れ層から10次元の出力層に変換し(ここではラベルが10の為)、softmax関数を使い正規化します。
まとめ
カラー画像(3チャンネル)ではもう少し処理が複雑になりますが、とりあえず畳み込みニューラル・ネットワークの大まかな流れをつかむことが出来ました。
「機械が自分で『学習する』ってどういうことなんだろうか?」
そんな子供が持つ様な疑問を解消するために色々読み書きしてきましたが、理解できたことは3点。
- 畳み込みニューラル・ネットワークによりデータを抽象化することが出来る。
- ニューラル・ネットワークは損失関数を元に損失を減らすことが出来る。
- 機械学習は元になるデータが重要である。
うう。改めて見ると大したこと分かってない…。けれどもSFの世界でしかみられなかった人工知能の世界に一歩近づけた様な気がしてちょっぴり嬉しいです。ではまた。