さて、数式をウェブ上で書くのにも(LaTeXというそうです)少し慣れてきましたので、Machine Learning - Coursera で学習したことをちょっとまとめてみます。
仮説(Hypothesis)
訓練データセット$(x,y)$を元にして、仮説$h_\theta(x)$を立てます。
$$
h_\theta(x) = \theta_0+\theta_1x\
$$
これは線形回帰(単回帰)と呼ばれます。
目的関数(Cost Function)
訓練データセット$(x,y)$を元にして、仮説 $h_\theta(x) = \hat{y} $ が $y$ に最も近づく様にします。
訓練セット一つ一つ($m$)に対して誤差の総和を求め、全ての点の誤差が最小であるパラメータ $\theta$ を求めます。
これは二乗誤差法と呼ばれます。誤差はプラスとマイナスがあるので、二乗してプラスにし、線形のプラスマイナスの差分を均一にするため $\dfrac {1}{2} $ します(多分。これで合ってるかな?)
仮説 $h_\theta(x) = \hat{y} $ ですので、以下の様に表すことが出来ます。
$$J(\theta_0, \theta_1) = \dfrac{1}{2m} \displaystyle \sum _{i=1}^m \left ( \hat{y}_{i}- y_{i} \right)^2\\ J(\theta_0,\theta_1) = \dfrac{1}{2m}\displaystyle\sum _{i=1}^m \left (h_\theta (x_{i}) - y_{i}\right)^2\\$$最急降下法(Gradient descent)
仮説のパラメータは $\theta_0, \theta_1$ の2つの変数を持つので、目的関数 $J$(cost function)をプロットすると3次元になります。
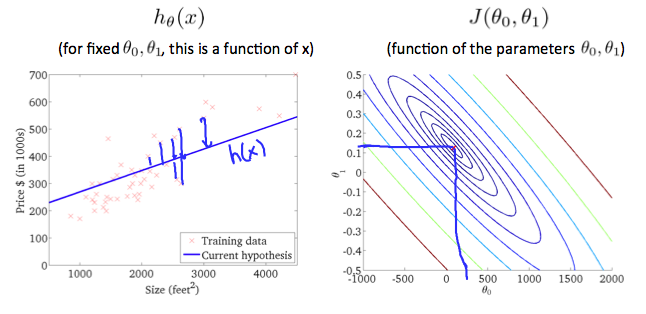
画像引用: Machine learning - Coursera
目的関数の最小値を求める為にこれを導関数を利用して微分します(実際は変数が複数あるので偏微分)
最小値を求める為にパラメータ $\theta_j$ を上書き(更新)して行きます。(複数のパラメータは同時に更新します)
単純に微分するだけでなく、収束を早め、精度を上げる為に学習率 $α$ を掛けます。
$$\theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1)\\ (for\ j = 1\ and\ j = 0)$$これは最急降下法(Gradient descent)と呼ばれます。
最急降下法に目的関数を代入する
最急降下法(Gradient descent)に目的関数を代入することで、局所最小値が求められます。
$$\theta_0 := \theta_0 - \alpha \frac{1}{m} \sum\limits_{i=1}^{m}(h_\theta(x_{i}) - y_{i})\\ \theta_1 := \theta_1 - \alpha \frac{1}{m} \sum\limits_{i=1}^{m}(h_\theta(x_{i}) - y_{i}) x_{i}$$では。
参考にさせて頂きました
Coursera Machine Learning (1): 機械学習とは?単回帰分析、最急降下法、目的関数 - Qiita