さて、Courseraの機械学習講座も折返し地点を過ぎ、様々なアルゴリズムの解説へと進んで行きます。今回はサポートベクターマシンです。
丁度1年前、この記事 ではじめて機械学習をやってみました。10種類のワイン成分データを元にして、8段階のおいしさランクに分類するという例題です。
何も考えずに scikit-learn の標準的アルゴリズム SVM を利用していました。こんな感じ。
|
|
ライブラリを使えばpythonでたった3行で学習させる事が出来るのですが、さてこのアルゴリズム、先週まで利用したロジスティック回帰と何が違うのでしょうか。
ロジスティック回帰との違い
ロジスティック回帰との比較に関しては以下の記事で詳しくまとめられています。
Coursera Machine Learning (7): サポートベクターマシーン (SVM)、カーネル (Kernel) - Qiita
こちらを参考に自分なりにまとめてみます。
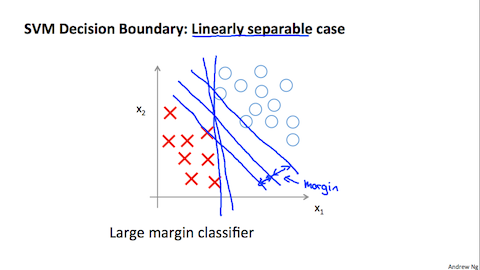
画像引用:Machine Learning -Coursera
これがSVMの分類です。ロジスティック回帰はこんな感じで分類しました。
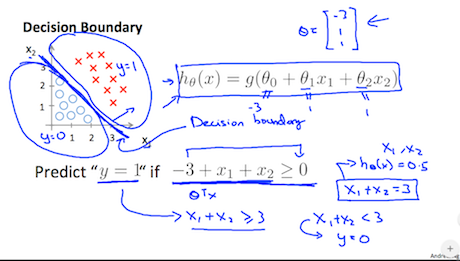
画像引用:Machine Learning -Coursera
ロジスティック回帰では仮説はシグモイド関数に予測変数のパラメーターを代入し、
- $h_\theta(x)>0.5$ なら $y=1$
- $h_\theta(x)\leq 0.5$ なら $y=0$
となることで分類出判定を行いました。目的関数を最小にするには、予測変数のパラメーターを最急降下法の式に代入します。
SVMは少しやり方が異ります。
目的関数を最小にする為に最急降下法を使うのは同じなのですが、分類のマージンを最大化する為にロジスティック関数よりシンプルな関数を使います。
そして目的関数の最小値を求める際、「内積」を利用します。内積に関してはこちらの高校生向けのサイトが参考になりました。
ベクトル 内積の公式&高校生必見のよくある間違いとは? - 受験のミカタ
線形SVM
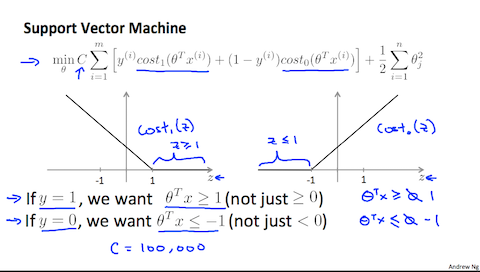
画像引用:Machine Learning -Coursera
SVMでは目的関数を算出するのにシグモイド関数(ロジスティック関数)の代わりに上記の図の様な関数を利用します。
- $y=1$ のとき$z \ge 1$ ならばコストを0にする
- $y=0$ のとき$z \le -1$ ならばコストを0にする
これを利用した目的関数は以下の様に表せます。
$$\min_{\theta} C \sum^m_{i=1} [y^{(i)} cost_1 (\theta^{\mathrm{T}} x^{(i)}) + (1 - y^{(i)}) cost_0 (\theta^{\mathrm{T}} x^{(i)})] + \frac{1}{2} \sum^n_{i=1} \theta^2_j$$最初の$\sum$ 部分は条件を当てはめると0になるため
$$\min_{\theta} C +\frac{1}{2} \sum^n_{i=1} \theta^2_j$$ $$s.t. \hspace{15pt} \theta^{\mathrm{T}}x^{(i)} \ge 1 \hspace{10pt} if \hspace{5pt}y^{(i)} = 1 \\ \hspace{30pt} \theta^{\mathrm{T}}x^{(i)} \le -1 \hspace{10pt} if \hspace{5pt}y^{(i)} = 0$$この課題を最小値することがSVMの課題になります。
微分の代わりにSVMではベクトルの内積 (Inner Product)を利用して決定境界 (Decision Boundary)を決定します。
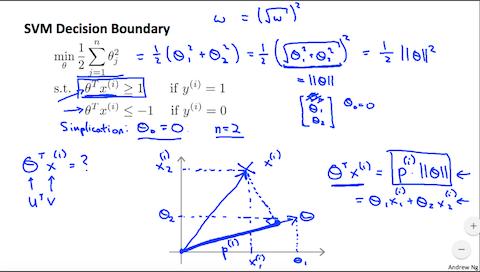
画像引用:Machine Learning -Coursera
ここでは内積の定義を利用してパラメータ $\theta$ を算出するという理解に留めます。
SVMは非線形分類を行う事も出来、これはカーネル(Kernel)と呼ばれます。
ここまで必死に板書を書き写してみましたが、ロジスティック回帰の様に視覚的にパラメータが降下していくアルゴリズムではない為、イメージが掴みづらく理解が難しかったです。
アンドリュー先生は講義の中でこんな風に説明しています。
サポートベクタマシンアルゴリズムは 特定の最適化問題を導く。 だが以前のビデオで 簡単に述べた通り、 パラメータシータを解くソフトウェアを 自力で書く事は、全く推奨しない。
SVMの最適化問題を 解くソフトウェアは、 とても複雑だ。
であるから、自分で実装しよう、なんて考えないで それらの高度に最適化されたソフトウェアライブラリのどれかを使う事を 強く推奨する。
アルゴリズムの選択
講義の最後にいつ、どんなアルゴリズムを使うべきか解説がありました。特徴量の数量とデータセットの数によって適正なアルゴリズムを選択することで精度の高い分類が行なえます。
また学習時間は多く掛かるものの、よく計算されたニューラルネットワークはどの条件でも上手く機能するだろうとまとめられています。
参考にさせていただきました
Coursera Machine Learning (7): サポートベクターマシーン (SVM)、カーネル (Kernel) - Qiita